Tech lessons from Overwatch 2’s server troubles
Edgegap CEO Mathieu Duperré offers advice on how to overcome (or at least prepare for) infrastructure issues when launching a multiplayer game
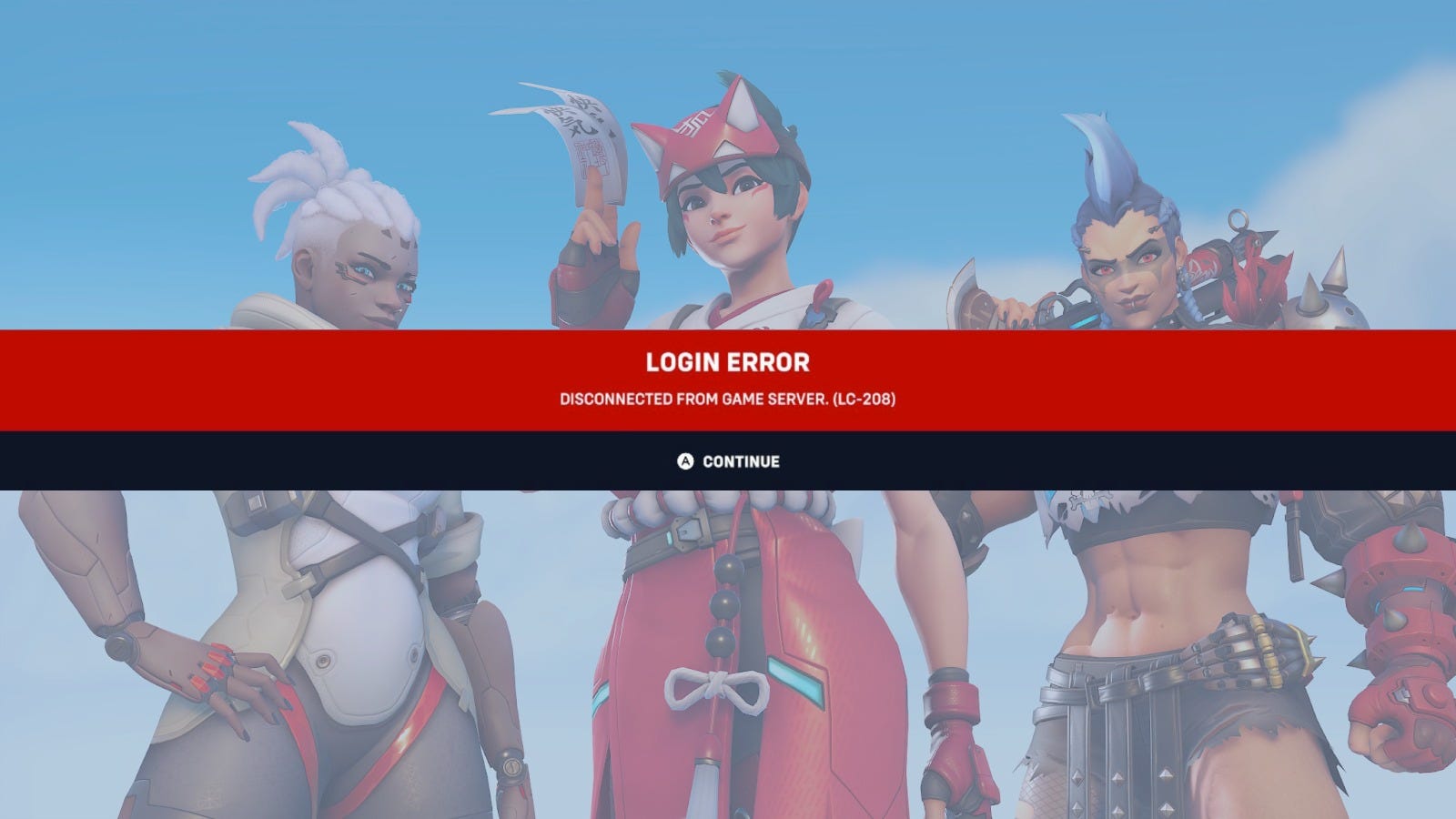
Server disconnects, black screen issues, DDoS attack, failed log-ins, and endless queues – the launch of Overwatch 2 didn’t exactly go as planned, did it? Or maybe it did, because we seem to have reached a point where players now expect online multiplayer features for AAA games to be broken at launch.
Forza Horizon 5, Splatoon 3, Halo Infinite, and Battlefield 2042 are just some of the games released in the last year that have suffered major network infrastructure issues at launch. Overwatch 2 may be the latest game to be affected, but it certainly won’t be the last.
With that in mind, it’s reasonable that many are left wondering where things are going wrong and if there’s anything that studios can do to avoid their games suffering the same network woes experienced by Overwatch 2.
Why do AAA games keep struggling with infrastructure issues?
There’s a reason why infrastructure issues often persist for weeks and sometimes even months following the launch of a new game: diagnosing these issues isn’t easy.

Developers often need to work through a massive list of potential problems until they figure out what’s wrong. And even then, remedying that initial problem could lead to another one arising. Take the Overwatch 2 launch, for example. Blizzard suffered massive disruption on its servers, and several weeks after release, some of these problems are still ongoing.
So, what’s causing these problems? While there’s no way of pinpointing Overwatch 2’s infrastructure issues to a single issue, we can look at the standard network infrastructure for AAA shooters like Overwatch and some of the things I’ve witnessed first-hand from my time working with AAA studios.
Often, most of these problems boil down to a handful of specific issues:
Most AAA games use centralised servers
Most game studios use multiple centralised servers to handle all of the major data processing and management functions for their game(s). While there are benefits to centralised servers, such as them generally being more cost-effective and easier to manage and deploy, there are some significant downsides, too.
All of your most valuable data is stored in very few points. This puts a massive target on your back for DDoS attacks
All of your most valuable data is stored in one (or very few) points. This means you put a massive target on your back for DDoS attacks, as taking down a centralised server can take down the entire network in the corresponding area. In addition, centralised servers can create bottlenecks for your players. When players complain about network congestion in games, it’s not technically an issue with a ‘lack of servers’ as much as it is traffic congesting the single node in a centralised server.
Specific hardware requirements
Many larger studios run their game(s) on very specific hardware with low availability worldwide, such as CPU running at 4Ghz+ for Unreal servers, which can make scaling these games difficult. Game instances with many players per instance will require a faster and more powerful CPU, thus resulting in harder-to-find resources.
Things can get even more challenging when QA teams only certify game servers on a specific server model, forcing the DevOps/LiveOps team to struggle when traffic surges occur. This is frustrating when other models could be used, but the desire to follow a specific QA procedure prevents them from expanding to other providers/vendors: “We’ve always done it this way, so we need to carry on doing it this way.”
High-density hardware
There’s a temptation amongst studios to use large servers with as many CPU cores as possible to save money. They end up with an extremely high density of players per physical node, meaning any attack/issue to one node will have a ripple effect on thousands of players. This results in the same risks as using centralised servers: they become a much easier target for hackers/DDoS due to the density and single point of failure.

What are the answers to these infrastructure issues?
Regardless of the size of your studio, planning for infrastructure issues is challenging.
That said, there are some simple answers to the problems mentioned above. How useful they are, of course, will depend on whether or not you’re using centralised servers and the type of hardware your network is running off.
Use distributed servers rather than centralised servers
In a distributed network, all of your data processing and network management is distributed across the entire network rather than running off a central location. Not only is a distributed network more flexible and highly scalable – as you can add new servers whenever they’re needed – but you can also spread those servers geographically across multiple sites. This distributes your server load evenly to reduce bottleneck risk while eliminating any major outages that would arise from a DDoS attack on a centralised network. On top of that, distribution can also be achieved through multiple providers, thus mitigating the risk of service outage would a provider experience problem.
Forecasting how many players will play your upcoming new game is like trying to predict the weather in two months accurately
Use a cloud/edge infrastructure provider
One of the easiest ways to reduce the number of dropped connections that players experience, as well as other network issues, is to integrate with a cloud-based or edge infrastructure provider. Edge servers can also help address low latency and high bandwidth by positioning your players closer to servers, reducing the distance that data needs to travel.
When it comes to the equally essential and dreaded testing phases of your online game, there are bound to be hiccups, but operating and testing your game on multiple infrastructure providers and widely available machines can help mitigate the risks of disruption and flag any potential issues in advance. For example, work with platforms and partners that don’t require additional internal resourcing through multiple engineers and DevOps teams – this will save you time and money.
Automation, automation, automation
Today’s infrastructure, combined with the diversity of the services that studios offer, often results in complex puzzles. What used to be manageable by a few scripts made by a system administrator is no longer the case. Automation and deployment solutions such as Kubernetes, containerized payloads, microservices, and CI/CD solve problems but also bring new challenges.
The only way to leverage a better (and more complex) infrastructure is through serious automation. While studios have an excellent team of engineers, those engineers should focus on developing the best game they can make. Asking them to rebuild existing tools to automate infrastructures – when there are tools on the market today to do exactly that – is not the best use of a studio’s resources.
The reputational and financial costs of poor infrastructure management
Significant financial repercussions exist when a popular multiplayer game is downed for even the shortest period. As an example, Blizzard has moved Overwatch to a free-to-play model. In the absence of a hefty price tag, Blizzard’s primary revenue stream for Overwatch 2 will come from in-game purchases – imagine how many it’s missed out on in its first few weeks through players not being able to connect to matches or simply abandoning the game due to issues and promising not to return until it’s fixed.
Another example is Roblox, which generates more than $5 million daily. What were the financial implications of the outage they experienced for three days in November 2021 following its collaboration with Chipotle? (This definitely had nothing to do with the Chipotle collaboration, according to Roblox, despite the huge traffic surge and pressure on its servers it experienced as a result.)
Be open-minded about flexibly leveraging infrastructure instead of relying on a static infrastructure with no way out when problems inevitably arise
Then there’s the more significant issue of efficiently provisioning enough servers to meet the demand for the launch of a new game or an update. Forecasting how many players will play your upcoming new game is like trying to predict the weather in two months accurately. We’ve seen cases where major AAA titles that were supposed to get millions of players falling flat at launch and other instances in which a one-person army game dev launched a game that picked up millions of players overnight.
What’s the solution?
Again, flexibility is the answer. Some studios may be tempted to heavily overprovision, with upper management cutting a deal to provision hundreds of additional servers but making that deal based on a long-term contract. What happens if your game does enjoy a successful launch, but your player count quickly drops off shortly after launch (which is likely, by the way)? This will leave you with hundreds of servers you’re paying for but aren’t using.
No matter how short they last, infrastructure issues can cause long and adverse problems for the games they impact. With so many new games entering the market, players experiencing significant issues at launch might simply abandon that game and move on to something else.
Look at the recent launch of the game World War 3 and its server problems as an example. Angry players took over the Steam marketplace and review-bombed the game to express their frustrations. This reflects poorly on potential other players and ranks down the game in the marketplace, which cuts visibility.

What will Overwatch 2 do next?
If Microsoft's acquisition of Activision Blizzard is successful, the company might try to move more of its resources onto Azure's cloud infrastructure. However, we've seen in the past that relying on a single cloud provider isn't a perfect solution, such as Halo Infinite's ongoing infrastructure issues on Azure.
While it makes sense for Blizzard to leverage Azure as their primary service provider, the company should consider the long-term plan for Overwatch 2 and pursue additional infrastructure partnerships beyond this relationship. Adding non-Azure providers will mitigate the risk of infrastructure issues for Overwatch 2 due to the ability to switch or have a ‘backup’ when things go wrong, increasing the overall quality of the service and player experience.
The takeaway is to be open-minded about flexibly leveraging infrastructure instead of relying on a static infrastructure with no way out when problems inevitably arise. Current cloud and server providers want steady business to have predictable forecasts and revenue. The traffic flow for every online game out there doubles, if not triples, over the first 24 hours, making this a nightmare to deal with both from a technical and business point of view.
Thankfully, there are new generations of flexible solutions on the market to fill that gap and ensure game launches will enjoy the best experience while having a minimal impact on the studio's bottom line.
Mathieu Duperré is the CEO and founder of Edgegap, a pioneer in the edge computing industry and automation.
Sign up for the GI Daily here to get the biggest news straight to your inbox