Overview on popular occlusion culling techniques
The experts at Umbra share their knowledge on solving the 3D visibility problem
Video games at the top end of the field continue to get more visually detailed year after year - you only need take a look at any long-running franchise, from Grand Theft Auto to The Witcher series, to see proof of that.
But more intensive graphics require more processing power, something that's not always available to developers in between console refreshes or on mobile platforms.
One of the tricks coders have at their disposal is occlusion culling - dropping the need to process elements that are blocked from view - but there are several different ways to go about it, which we'll talk about in detail here.
Getting assistance from the GPU
Generating a depth buffer with occluders can be costly and demanding on system resources, and some fixes look to leverage the GPU for these operations.
This is the case of the "depth buffer reprojection" technique, where the idea is to use the depth buffer from the previous frame and reproject it to match the current frame.
Bounding boxes can be software-rasterized against this new buffer as a cheap way to know if a group of meshes is occluded or not, and the strength of this approach is it takes advantage of past computation to avoid generating a brand new depth buffer.
Integration into an existing engine is also quite simple and there is also no requirement to classify meshes as occluder or occludee - objects that hide other elements or objects that are themselves hidden - which further frees up resources.
There are drawbacks though. Being a temporal solution, it's subject to artifacts whenever the reprojection is performed. Meanwhile, fast-moving objects and abrupt camera changes can also significantly bring down the efficiency of the culling process.
Pushing the idea further, the GPU can be used not only for depth buffer generation but also for the occlusion queries themselves.
Unreal Engine 4, for example, relies only on the GPU to cull dynamic geometry in real-time by using a hierarchical depth buffer (generated by the GPU during a depth pre-pass) combined with GPU occlusion queries: bounding boxes encompassing a set of meshes are sent to the GPU to be checked for visibility against the scene depth buffer.

While GPU occlusion queries provide good results, the main issue here is latency: the engine will only read the query results with a single frame lag at best so as not to stall the GPU pipeline. This can lead to poor culling when the camera moves fast, as the system needs several frames to converge and reach optimal performance.
Delegating everything to the GPU
Another option for dealing with a massive increase of geometry in open environments is to delegate all the occlusion processing and decisions on what is rendered to the GPU.
It works by modifying the internal engine pipelines to make the GPU as independent as possible from the CPU - the rationale is that synchronization between CPU and GPU is very costly, since it degrades the GPU pipeline performance, and ideally the GPU should handle all the culling and rendering without relying on any CPU data.
One approach to the GPU-heavy method is to use a mesh cluster rendering technique, where the geometry is subdivided into clusters. The GPU can then independently perform culling and rasterization of these clusters in separate batches.
And it's a method that delivers very good results, both for dynamic and static geometry, and with minimal lag. It also offers a much higher granularity: while various other techniques classifies a mesh as either hidden or visible, this one works at a sub-mesh scale, culling only some part of the mesh but keeping others.
On the downside, technique requires fairly modern hardware with some serious computing ability - which is why you often see it on games intended for top-level kit - and it's difficult to integrate into existing code or traditional renderers. Crucially, the engine used must support asset subdivision necessary for mesh cluster rendering.
Using only the CPU
Some techniques go completely the other way, relying solely on the CPU to cull the occluded meshes, without touching the GPU, making them suitable for hardware where graphics power might be limited.
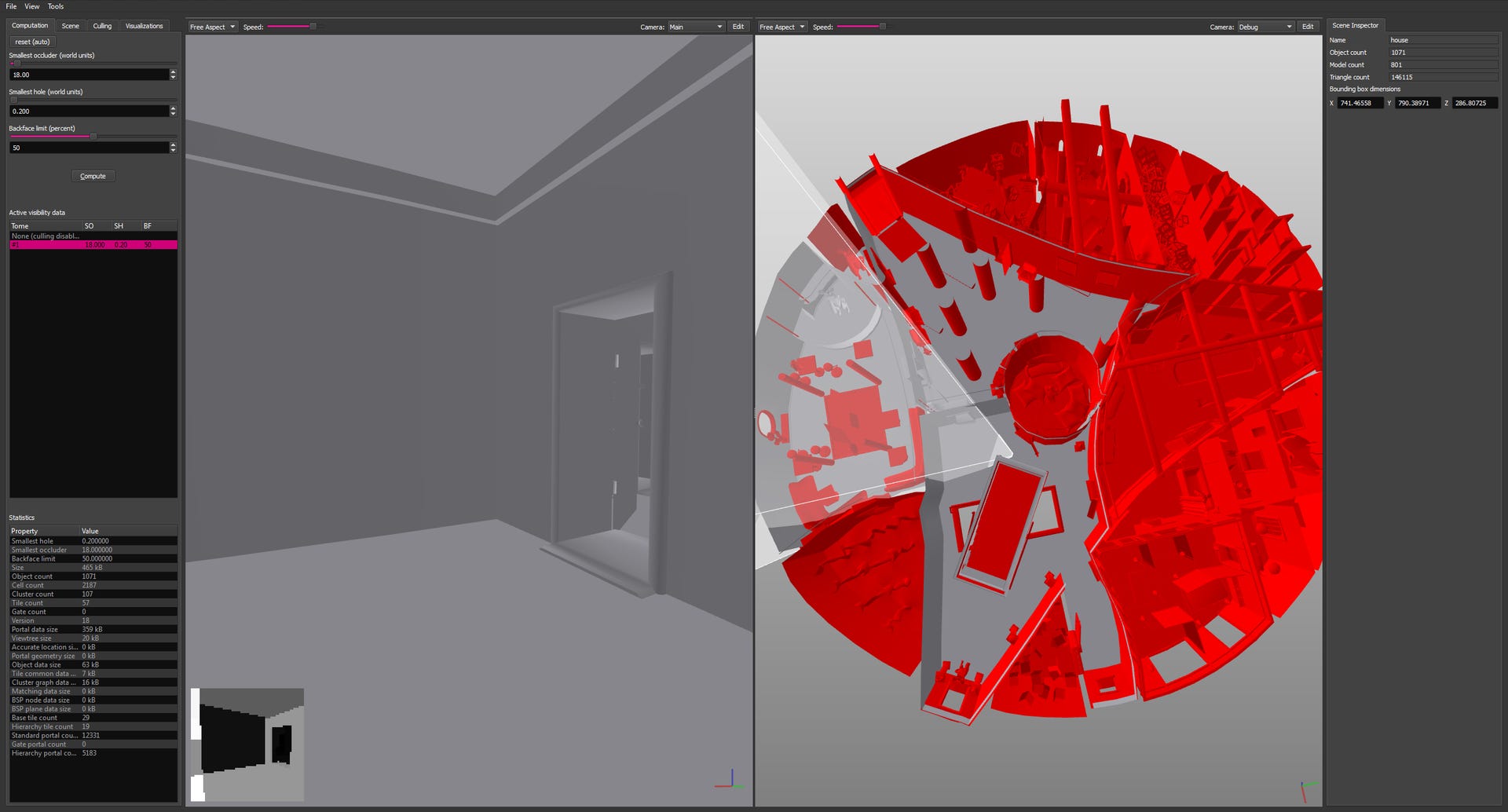
An example of one of these pure software solutions is our own Umbra, a middleware used in several high-profile titles and adopted as the default culling solution in the popular Unity3D engine.
Umbra pre-processes the scene offline, voxelizes it, then structures it into portals and cells to create a spatial database used at runtime. Queries can then be performed in real-time and involve the generation of a low-resolution hierarchical depth-buffer of the scene, performed by an highly-optimized software rasterizer.
One advantage of the CPU approach taken Umbra is that portal generation, which historically involved tedious work by the game artists, is now taken care of automatically.
Meanwhile, runtime queries can be multithreaded and return results extremely fast - a matter of milliseconds - which beats beating the high latency of GPU occlusion queries.
Although there are a few manual requirements (each world mesh must be assigned its own unique ID by the engine, for instance), Umbra is also easy to integrate into any game engine by accepting a polygon soup as input and returning a generic list of visible meshes that the engine can then render.
Finally, the spatial database in such a system can be used to speed up and implement other engine operations, such as audio occlusion and propagation.
It makes sense on a lot of levels and recently Intel also published another example of a purely CPU-based solution - similar to the Umbra technique, occluders are software-rasterized to create a hierarchical depth buffer.
One particularity is that this algorithm can take advantage of the SIMD capabilities of modern CPUs to speed-up the occluder triangles rasterization process - 256 pixels can be treated in parallel.
Intel says its algorithm has a very low memory overhead, is three times faster than previous approaches, and matches 98 percent of all triangles culled by a full resolution depth buffer approach.
The technique is also able to interleave occlusion queries at the same time the depth buffer is being constructed, leading to a more efficient traversal of the scene structure.
Perhaps the only downside is Intel's approach relies on specialized instruction sets available only in very recent CPUs, which closes the door to the current generation of consoles and smartphones.
The precomputed way
Speaking of smartphones, our constant companions are always with us but have very limited computing power compared with a gaming PC or console, which makes real-time occlusion culling something of a luxury.
On such devices UE4 doesn't use the CPU or the GPU at all, instead falling back to the older technique of "precomputed visibility volumes", where the scene is divided into several cells, and a set of visible geometry is calculated offline beforehand for each one.
The culling is performed at runtime by checking the cell the player camera is currently inside, and retrieving the list of non-occluded meshes.
This is a simple technique but suffers from some limitations, as you would expect: dynamic geometry or mesh streaming is not supported, and large levels suffer from poor performance due to an increasing number of cells.
It's clear then that's there's no 'one size fits all' approach to occlusion culling, and the right approach depends on the game style, intended platform, legacy issues and various other considerations.
However - along with Intel - we think that CPU-based occlusion culling is the most efficient, forward-looking approach to this crucial part of scene rendering, which also allows scope to pick a balance between performance and graphics fidelity as needed. You can find out more about occlusion culling at umbra3d.com